Why 70% of Self-Built Agentic AI Projects Will Fail by 2028
Gartner threw out a scary number. Iria Fredrick Victor explains why the real failure rate is even higher — and the three mistakes most teams make before writing a single line of code.

By 2028, analysts predict 70% of self-built agentic AI projects will fail to scale. But here's what the report doesn't tell you: most of those failures happen in the first six weeks. Not because the technology isn't ready — but because teams skip the architectural thinking that separates a demo from a deployment. Iria Fredrick Victor breaks down the three killer mistakes, why your LangGraph prototype won't save you, and the single question you must answer before writing any agent code.
Let me give you the number that keeps me up at night.
Seventy percent.
That's what the analysts are saying. By 2028, seven out of ten self-built agentic AI projects will either be abandoned, rewritten, or quietly hidden in a drawer labeled "lessons learned."
And here's my problem with that number: it's optimistic.
From what I've seen in the trenches — consulting, debugging, and rebuilding other people's agent failures — the real number is closer to 80 or 85 percent. Most teams just haven't admitted it yet.
I'm not writing this to scare you. I'm writing this because I've watched brilliant engineers make the same three mistakes over and over. And every single one of those mistakes was avoidable.
Let me show you what they are — and how you become part of the 30% that actually ships.
Mistake #1: You Built a Demo, Not an Architecture
Here's the most common conversation I have with teams:
Them: "Our agent works perfectly in testing."
Me: "What happens when two users ask different questions at the same time?"
Them: "...we haven't tested that."
Me: "What happens when the model calls the wrong tool because the user phrased something weirdly?"
Them: "We have retry logic."
Me: "What happens after the fifth retry?"
Silence.
The demo works. Of course it works. You hand-picked the examples. You tuned the prompts to those exact scenarios. You ran it on a laptop with zero latency and infinite memory.
Production is not a demo.
Production is:
- Users who type things you never imagined
- API rate limits you forgot existed
- Memory that fills up and starts dropping context
- Models that change behavior overnight because OpenAI pushed a silent update
The teams that survive build for the edge cases from day one. They don't say "we'll handle that later." Because later never comes.
Ask yourself right now: What's the ugliest, most confusing, most contradictory user input you can imagine? Does your agent handle it gracefully? Or does it crash, loop, or hallucinate?
If you hesitated, you're already in the 70%.
Mistake #2: You Confused Tools with Understanding
This one hurts because I've made it myself.
You give your agent access to a search tool. A database tool. An email tool. It calls them perfectly. You feel like a genius.
Then a user asks: "Can you summarize what my team worked on last week?"
Your agent calls the search tool. Gets 47 different messages. Tries to summarize them. Misses the context that two of those messages were jokes. Returns a summary that says your colleague "quit in frustration" when they were clearly being sarcastic.
The agent used the tool correctly. It just didn't understand what it was reading.
This is the hidden trap of agentic systems. Tool calling is easy. Interpretation is hard. And most teams stop at "it called the right function" without ever asking "did it use the result correctly?"
Here's what I do now: I test the interpretation, not just the invocation.
I give my agent a tool result that's ambiguous, contradictory, or incomplete. Then I watch what it does. Does it ask for clarification? Does it flag uncertainty? Or does it confidently return garbage?
The last one is the 70% answer.
Mistake #3: You Have No Exit Strategy
This sounds pessimistic. I promise it's practical.
Every successful agentic project I've seen has a clear answer to this question: "What happens when the agent doesn't know?"
Not "when it fails." When it doesn't know.
Because here's the truth: your agent will be uncertain constantly. The model will have low confidence. The user's question will be outside your documentation. The tools will return empty results.
The 70% of failing projects try to make the agent guess anyway. They add more prompts. More few-shot examples. More pressure on the model to "just try."
And the model complies. Confidently wrong. Every time.
The 30% do something different. They build graceful uncertainty into the architecture.
That looks like:
- A clear "I don't know" response that admits limitation
- A handoff to a human with full context preserved
- A fallback to a simpler, rule-based system for basic queries
- Or my favorite: a request for clarification that actually helps the user refine their question
Your agent doesn't need to be omniscient. It needs to be honest about what it doesn't know.
Write this down: The most reliable line of code in your agent pipeline should be the one that says "I'm not sure. Let me ask a human."
The Real Reason Gartner's Number Might Be Low
Analysts look at data. I look at codebases.
And what I see in most self-built agentic projects is architectural debt — the kind that doesn't show up in the first month, but crushes you by month six.
It looks like:
- Agent loops that nobody can trace because the logic is scattered across 15 files
- Prompt changes that break three other behaviors without anyone noticing
- Tool definitions that conflict because two engineers added overlapping functions
- Memory systems that corrupt themselves when the conversation exceeds 50 turns
None of this is the model's fault. It's the glue — the code you wrote to connect everything together — that's rotting.
The teams that succeed treat agent architecture like software architecture. They don't hack. They design.
They use declarative DSLs (I wrote about this — go read it). They add verification layers. They test uncertainty. They build for production, not for a demo next week.
That's the difference between 30% and 70%.
How to Join the 30% (Starting Tomorrow)
You don't need to scrap your project. You need to ask four hard questions:
Question 1 – What's your single point of failure?
If one tool, one prompt, or one model call breaks, does everything break? If yes, redesign.
Question 2 – What happens at the edge of your knowledge base?
Find the weirdest, most out-of-domain question you can think of. Run it today. Watch what happens.
Question 3 – Can you explain every decision your agent made in the last conversation?
If you can't trace it, you can't fix it. Add logging that shows reasoning, not just outputs.
Question 4 – When was the last time your agent said "I don't know"?
If it's been more than a day, your agent is guessing too much. Dial down the confidence.
Answer those honestly. Fix what breaks. Repeat every week.
That's not magic. That's engineering.
The Brand Takeaway (How Iria Fredrick Victor Gets Noticed)
Here's what I want people to think when they see your name on an article:
"Fredsazy doesn't sell hope. Fredsazy sells what actually works in production."
Anyone can post a notebook with a working agent. The internet is full of them. But the people who get remembered — who get quoted in strategy meetings, who get invited to speak, who get the consulting retainers — are the ones who talk honestly about failure.
Not to be negative. To be useful.
I write about the 70% so you can be in the 30%. That's my brand. That's what I want you to take from every article I publish.
Now go break your agent on purpose. Fix it. Then do it again. That's how you ship.
One Last Thing From Me — Fredsazy
Pick the ugliest user question you can imagine. The one that makes you nervous. Run it against your agent today.
If it handles it well, congratulations — you're ahead of most teams. If it doesn't, you just found your next week of work.
Either way, you're closer to the 30% than you were before reading this.
That's the point.
Written by Iria Fredrick Victor — because 70% is a statistic, but your project doesn't have to be.

Iria Fredrick Victor
Iria Fredrick Victor(aka Fredsazy) is a software developer, DevOps engineer, and entrepreneur. He writes about technology and business—drawing from his experience building systems, managing infrastructure, and shipping products. His work is guided by one question: "What actually works?" Instead of recycling news, Fredsazy tests tools, analyzes research, runs experiments, and shares the results—including the failures. His readers get actionable frameworks backed by real engineering experience, not theory.
Share this article:
Related posts
More from AI
May 27, 2026
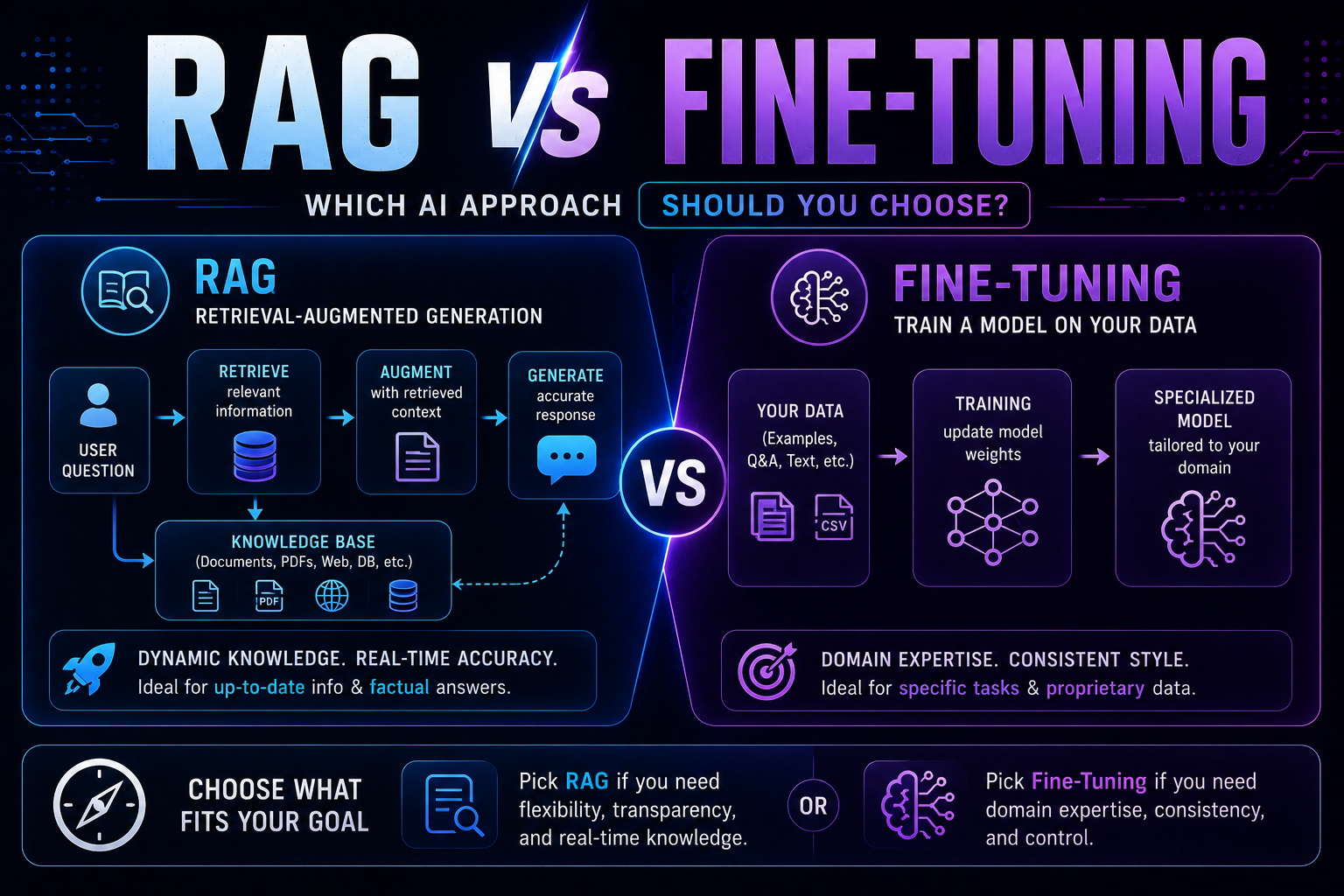
130RAG vs fine-tuning in 2026 — a practical guide covering when to use each, how both work with real code examples, the form vs facts distinction, hybrid approaches, true costs, and a decision framework to choose the right AI architecture for your use case.
May 22, 2026
1355 red flags every business must spot before buying AI software — covering demo manipulation, data privacy gaps, missing error handling, AI-washing, and lock-in contracts, with a 4-week vendor evaluation framework.

May 13, 2026
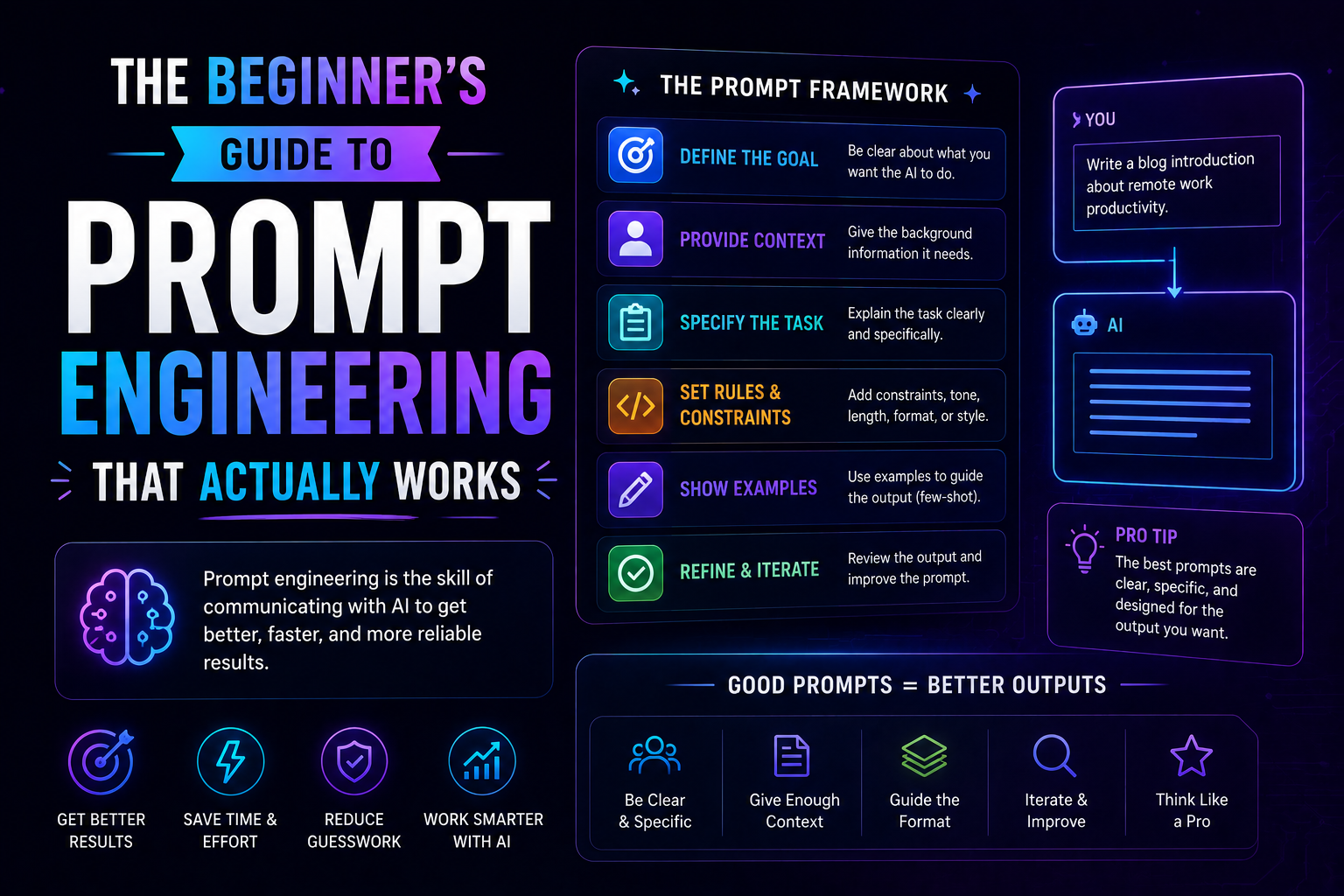
759The beginner's guide to prompt engineering that actually works in 2026 — covering the RCTF framework, chain of thought, few-shot examples, output contracts, and model-specific tips for Claude, GPT-5, and Gemini.